
隨著春節前後數個大模型陸續發佈,人工智能的網絡熱評已經從技術圈擴大到社會圈、朋友圈。
國內外好評與差評,熱捧與詆毀,在我看來都是浮雲,它既不會影響DeepSeek自身的迭代,也不會掣肘同行探索腳步。
事無絕對,DeepSeek也是同樣,今天就囉嗦兩句:從人工智能N落N起演進中,審視DeepSeek的中國式創新。觀點未必正確,不喜勿噴。
提及人工智能(AI)和現在火熱的大模型,有幾個問題擺在面前:
1.AI賽道中為什麼大模型當今被炒得這麼熱?
2.OpenAI做的ChatGPT真的不如DeepSeek嗎?
3.DeepSeek是未來AI發展的方向嗎?
我的回答:1.適者生存。2.不是。3.未必。
01
摸著時間脈落,先從AI起落沉浮說說發展史上幾個關鍵研究成果,然後再做比較。
互聯網上能看到太多的人工智能發展史或編年史,我就不贅述了。
上世紀40年代開始人工智能的混沌探索,其核心是想製造出類似人類思考和行動的機器。造出這個智能體:
1.你得跟人交互吧(如果人類語言不能直接聽懂,人類通過電腦發送通用指令應該被接受)
2.你得有所謂的邏輯思維和運算能力吧(其實人類也沒有完全搞清思維是怎麼回事,從神經元模擬開始,生物科學進一步,人工智能進一步)
3.你得能自如移動吧(例如機器狗和具身智能機器人)
科學家很早就知道,造一個鐵皮殼子很簡單,機器人的行為動作取決於它的大腦,所以設計它的思維模式才是根本。
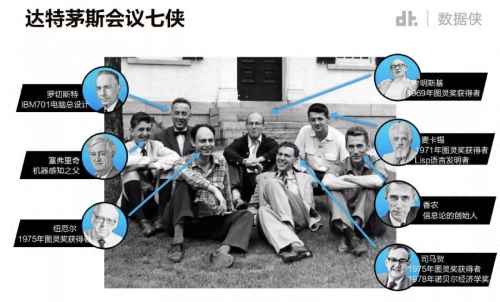
1956年,達特茅斯學院研討會上正式使用了人工智能(artificial intelligence,AI)這一術語後,早期的各種AI流派研究角度各有不同,他們做出了能夠證明部分定理的程序,也寫出了棋類簡單遊戲,研究過通過符號來解讀人類獲得知識的方式,但實話說來,從理論上並沒有研究出可行的路線。
那時的計算機編碼和邏輯推理設計,語言翻譯搞不定,視覺感知更別提,加之當時計算能力和數據存儲限制,也就是路線和能力皆不具備。摸著石頭過河,沒投資、沒技術、普世悲觀,AI寒冬紀。
02
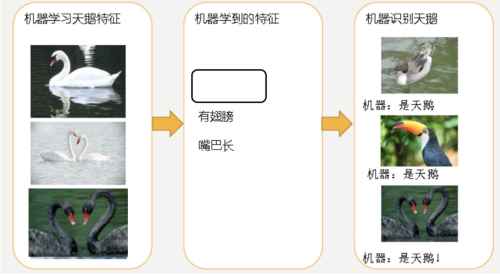
走的人多了,也便成了路。第一次橫空出世的引領者是機器學習(ML)走出新路線。
機器學習這個方法早在1959年就被提出,它的原理可以概括為處理數據、提取特徵、訓練模型、改進性能、給出結果。
是的,我們後來所知道的DeepBlue機器戰勝國際象棋棋王卡斯帕羅夫、AlhpaGo戰勝圍棋冠軍李世石和柯傑、某音某寶精准推送音樂和商品,不都是這條路線嗎。所以回頭看,人工智能的研究是選擇了機器學習這條賽道。
但為什麼會是機器學習呢?
我們看標黑字體的第四個,改進性能,沒錯,流程中加了改進性能,實際上包括了運用邏輯門電路(與、或、非)建立反饋機制,而這就是神經網絡的雛形。借一張C友的圖。
我只有不斷的糾錯反饋才能讓我變的更強大。好熟悉,有沒有。跳出歷史週期率的第二答案——自我革命。
言歸正傳,1982年,約翰·霍普菲爾德(John Hopfield)在自己的論文中重點介紹了具有記憶和優化功能的循環(遞歸)神經網絡(RNN)。
這個RNN突破在哪裡呢,傳統的機器學習神經網絡算法,輸入和輸出是直線。
RNN最大的區別在於每次都會將前一次的輸出結果,帶到下一次的訓練,這使得每一個後位數據都與前序數據產生關係影響,通過計算相似關係而預測後一數據。例如,我問What time is….它會根據前三個單詞的意思和與之關係,預測最後一個詞是it。
1986年,戴維·魯梅爾哈特(David Rumelhart)、傑弗里·辛頓(Geoffrey Hinton)和羅納德·威廉姆斯(Ronald Williams)等人共同發表了一篇名為《通過反向傳播算法的學習表徵》的論文。
在論文中,他們提出了一種適用於多層感知器(MLP)的算法,叫做反向傳播算法(Backpropagation,簡稱BP算法)。
BP算法是什麼,好比①②③④⑤五位同學傳信息,當信息傳到②號時,他在往③號傳的同時,還要向①號發送反向信息檢驗傳遞的準確性。
同理,③④⑤號同學也會逐個反向驗證,通過計算信息傳遞的損失,得出各位同學能力的大小個頭(稱為梯度),利用算法來調整梯度權重,從而最小化損失。
我認為RNN和BP的誕生是核彈級別,讓機器學習真正意義上活了,可行了,有路可走了,起碼是找到方向了。
這算是大創新,國際大獎的認可比較遲,直到2024年,約翰·霍普菲爾德與傑弗里·辛頓(Geoffrey E. Hinton)才共同獲得了諾貝爾物理學獎。Better late than never,發展進程不斷為後人探索已經證明了創新的價值。
03
循環遞歸神經網絡(RNN)和反向傳播算法(BP),確實是兩把好工具。但是在應用中不免遇到問題。比如,傳遞信息的同學太多,每個同學都要向後面所有同學確認,計算量越來越大怎麼辦?相鄰站位的同學大小個頭太接近,或者差距太大(梯度近似或失真),計算差值不準確怎麼辦?
1997年,德國計算機科學家於爾根·施密德胡伯(Jürgen Schmidhuber)與其弟子塞普·霍克賴特(Sepp Hochreiter)開發了長短期記憶網絡(LSTM)。
LSTM有什麼特別之處呢,它引入了記憶細胞、輸入門、輸出門和遺忘門的概念。
記憶細胞負責保存重要信息,輸入門決定要不要將當前輸入信息寫入記憶細胞,遺忘門決定要不要遺忘記憶細胞中的信息,輸出門決定要不要將記憶細胞的信息作為當前的輸出。
打個比方,當一本小說我看到中間部分時,離我當前最近的前一段落,可能是我記得最清楚的,而開頭的一此細節可能就記得不那麼清楚了,這叫短時記憶,前面提到的RNN就是那種短時記憶。離得越近,相互影響越強。
而LSTM會選擇重要信息並加以權重,那看到小說中間的時候,我還是會想起前面埋下的伏筆。
由此來看,LSTM是RNN的高級形式,與BP有異曲同工之妙。
但是德國大叔對自己成果在AI學界被忽視表示強烈不滿,批評同行、開噴Meta、怒懟圖靈獎,有點兒祥林嫂的感覺,有興趣的小夥伴可以自己搜來看。
另一個事件是2006年,傑弗里·辛頓正式提出深度學習概念。主要觀點是:多隱層的人工神經網絡具有優異的特徵學習能力,學習到的數據更能反映數據的本質特徵有利於可視化或分類。
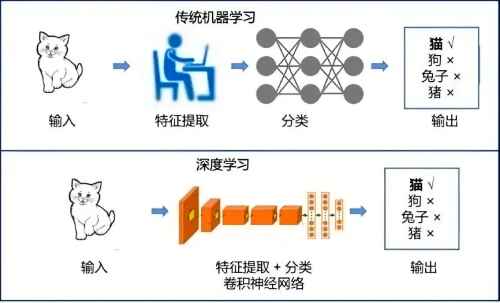
之前機器學習的RNN到BP、LSTM路線,構建的有輸入、有反饋、有權重、有輸出的循環模式。總體上它可以看作是簡單的神經網絡,也就是它就像在模擬生物神經元的工作方式來處理數據。這就是人工智能模仿生物神經元思維的路線。
單一的神經網絡只能對連續的序列(例如語音、文本)單線條的處理,而多線程直至1998年卷積神經網絡(CNN)的出現,就好比一台由無數神經元組成的並行機器,要有組織有規模的工作了。
可以想像這是比較耗費計算資源的一項工程,從此,人工智能研究正式開啓了算力比拼。
我認為相比LSTM和CNN這種導彈級別的成果,深度學習概念的提出是核彈級別的創新。
因為它引出一條看似可行的AI之路,終於使得原本用於圖像處理的芯片(GPU),參與到更加複雜的計算之中。芯片商業帝國從此重新劃分,原本的圖像領域單項冠軍英偉達(NvIDIA)市場份額逐漸超過CPU廠商Inter和AMD,獨領高性能計算風騷。
04
AI領域研究的大牛很多,自從深度學習被提出以來,借著大數據和計算機硬件的發展,使得深度學習得以乘勢推廣應用。
以此而生的深度神經網絡,在AlhpaGo戰勝圍棋冠軍李世石和柯傑過程中異常出彩。是的,研究室里的函數無法引起社會關注,廣告效應才會讓風投基金端著大把的金錢送到面前。新一輪的人工智能熱潮又將到來。
2017年12月,Google機器翻譯團隊發表了重磅論文《Attention is all you need(你所需要的,就是注意力)》,提出使用「自我注意力(Self Attention)」機制來訓練自然語言模型——Transformer。
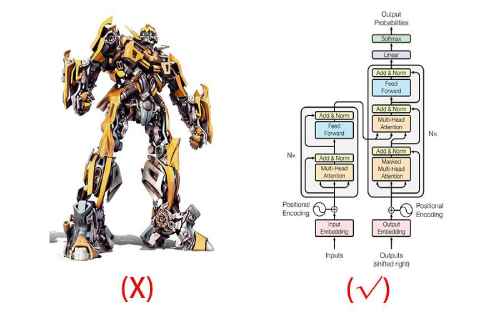
Transformer能夠有效捕捉序列信息中長距離依賴關係,相比於以往的RNNs,在處理長序列時的表現更好。自注意力機制的另一個特點是並行計算,因此Transformer結構讓模型的計算效率更高,加速訓練和推理速度。
Transformer的出現是核彈級別的創新,它徹底改變了深度學習的發展方向,研究者們以它為大模型基座,建立Transformer架構去搭建訓練模型,由此才衍生出一系列的深度學習產品。
接著要提到的就是ChatGPT的橫空出世,驚天一響,看到通用人工智能(AGI)真實落地進入人類社會的實現可能。看官們都比較熟悉,我就不多說了。
05
在這裡我想多說一句,當下的大語言模型(LLM)為什麼成為主流。
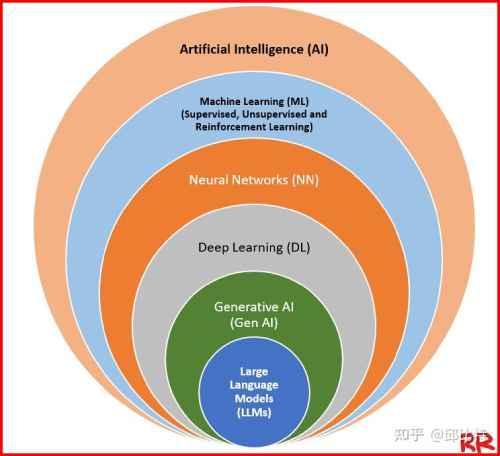
以上談到的人工智能發展,只是AI的一條主線,但不是全部。
當你從樹枝頂頭回望樹幹時,技術路線是如此清晰;而你站在地上沿著樹幹看向四處發散的蒼天大樹時,不一定知道哪條會長到理想的高度。
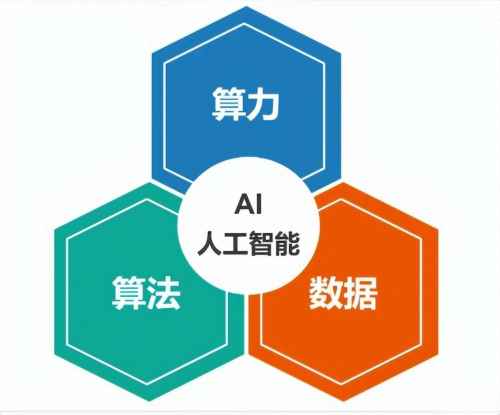
本質上來說,從機器學習到大語言模型是一條生物神經學+數學+統計學的融合道路,依賴於算法、算力和數據三大基本要素。
算法——好點子(生產工具),算力——好力氣(生產力),數據——基本盤(生產資源)。
讓機器學會學習,實際是訓練它先掌握人類的先驗知識,然後讓機器自己學會分析,最好能自己研究出新知識(生成式AI)。
拿下圍棋舉例,你給它上萬張棋譜,目的是訓練它記住,並且找到致勝規律,分析什麼時候走哪一步棋才是最優解。
做出一個承載算法、算力和數據的模型,讓它來實現真正的人機交互。這些模型有自然語言處理的(NLP:文本生成、機器翻譯、人機問答),也有計算機視覺的(CV:圖像識別、視頻生成)。反正就要整一個體量大、計算能力強的大模型,去封裝儲存你那些牛X的算法、昂貴的算力、海量的數據。
Transformer出生之前,AI的優先方向其實是視覺領域,大家都覺得深度學習和卷積神經網絡在解決圖像視頻方面更有出頭之日,而且並不看好機器翻譯和文本生成有什麼商業應用價值。
特別是2012年,傑弗里·辛頓(是他,是他,又是他)和他的學生Alex Krizhevsky設計的Alexnet,在圖像領域競賽獲得冠軍且大幅提升準確率,掀起一波研究應用高潮。
國內人工智能第一代「四小龍」——商湯、雲從、曠視、依圖,都是CV起家。風來的快,去的也快。阿里、海康威視等自研視覺算法達到一定程度後,「四小龍」基本上聽不到聲音了。人工智能在視覺領域的應用,並沒有孕育出新算法,也沒有拓展新場景。
如果落地應用(賺錢)不能反哺技術研究(或是說提出新需求,刺激技術創新),這條路走著走著就暗淡無光了。
反而是2015年成立的OpenAI堅持自然語言處理(NLP)創出了一片天。隨著Google和OpenAI確立「預訓練-基礎大模型訓練-指令微調-反饋優化-獎勵模型-強化學習」這一流程範式,大語言模型走上權力王座,不管步驟怎麼變,不管算法怎麼創新,你都得整個LLM出來。
參與入局玩家既有Google、Meta、阿里、百度、騰訊、抖音等大廠,又有OpenAI、月之暗面、DeepSeek等純AI公司,還有國字號的科研機構。
一時間,百模飛舞,頗有2000年前後互聯網新興之氣象。
06
寫到這裡,有些AI領域的技術成果(知識圖譜、貝葉斯網絡、無監督學習等)我沒有來得及說,不過也沒有關係,不影響大家對大勢的閱讀分析。
2024年12月,DeepSeek發佈通用模型V3。2025年1月20日,DeepSeek發佈推理模型R1。1月28日發佈多模態模型Janus-Pro-7B。
DeepSeek發佈的產品是不是劃時代的?與前文提到的BP、深度學習、Transformer具不具備同樣核彈級意義?是否改變了AI研究的進程?
帶著這些問題,我們從技術本身來看看DeepSeek從V3到R1的與眾不同之處。
特點一:強化學習(RL)的運用方式。強化學習是機器學習的一種方法,前面提到的大模型範式中,強化學習是其中的一個環節。
通俗來講,就好比一條狗在做對和做錯中,不斷挨打和得賞,這些獎賞使得它懂得調整自己做出的選擇,隨著獎賞積累越來越多,狗做出的選擇也越來越符合主人的意圖。
Alhpa的那條狗就是這麼馴的,效果不錯。
DeepSeek有什麼不同之處呢,在做出R1之前,DeepSeek做了一個版本叫做R1-zero,這個R1-zero沒有做預訓練和監督微調,沒採用通用的範式,直接上強化學習(RL)。然後在R1-zero基礎上,用少量的高質量標注數據再跑一次RL,做出了R1。
DeepSeek的試驗證明了強化學習的重要性、有效性、優先性,純RL也能做出推理模型。而且,如何運用RL,並不一定要刻板地遵守已有範式。
特點二:頓悟現象(Grokking)的精確表達。在我們的認知裡,機器就是機器,它把我們已有的知識學好用好就不錯了,「靈光一現」「開竅了」還得是人類。
機器「頓悟」現象是什麼?中科院院士陳潤生曾經形象的解釋過,「你訓練一個神經網絡的過程中,一遍它不懂,兩遍也不懂,第四遍還不懂,第五遍一下學會了,就像小孩學東西一樣,教一兩遍不懂,教到N+1遍突然就學會了。」
頓悟現象(Grokking)在大模型推理中出現,讓人類第一次感受到了機器可以產生的「高階思維」。
「頓悟」並不是DeepSeek最先發現的,Google和OpenAI的團隊在2023年就在大模型訓練時發現這一現象,並且對生成條件和原理做了一定的探索。
但是,DeepSeek把「頓悟」寫在公開技術文檔裡,並體現在應用的思考流程上,讓用戶看得到並且可以評判的。
當你用DeepSeek R1深度思考模式提出複雜問題時,模型會突然停下思考,自主修正推理路徑,甚至用自然語言標注出它在思考,然後給出思考後的答案。
不管你們怎麼看,當我看到屏幕前「等等,等等。這是一個頓悟時刻。讓我們一步一步地重新評估一下,以確定……」這些字符時,這一刻我是挺震撼的,之前頓悟只限於AI科學家的研究範圍,而DeepSeek把它帶到眼前。
特點三:蒸餾模型(Distillation)的巧妙設計。蒸餾也不是什麼新詞,聽上去高大上,葡萄酒蒸餾之後就是白蘭地,啤酒蒸餾之後就是威士忌,米酒蒸餾的話應該是二鍋頭吧。
大模型蒸餾其實也好理解,隨著大模型的參數越來越龐大,應用端在處理某一領域問題時其實用不上如此龐大的模型。如果我是一名擁有百科全書知識的老師,那我可以把我的數字知識教給一個學生,他就可以搞定數學方面的問題。
各個模型公司普遍都在做蒸餾,這是很正常的一種技術方法。
我女兒小學五年級,數字老師在班級每組指定了1個學習好的同學作組長,每日計算小測試題,老師把組長們的題先批改完,講清問題和方法,然後組長們就負責本組所有同學的批改和答疑。
DeepSeek 團隊在蒸餾方面是這樣做的,他們使用R1生成的數據,對友商(雷軍語錄)的多個小模型進行了微調。結果證明,蒸餾後的小模型,在推理能力上得到了顯著提升,甚至超越了在這些小模型上直接進行強化學習的效果。
雷軍說:友商是XX。友商氣不氣,真生氣。這幾天看到已經有人說數據抄襲了。
我覺得更應當關注的是,為什麼蒸餾後的小模型,比強化學習的效果要好。畢竟俗話都說,鳳凰下雞——一代不如一代。
DeepSeek的R1模型生成過程中有沒有直接蒸餾國外友商原模型數據,我不知道。但DeepSeek蒸餾的使用手冊,人家發佈的時候就寫在技術文檔裡的。我只想說,方法很巧,還可以進一步嘗試。
特點四:編程語言的神之選擇。這本來是個小事,最近兩天有新聞在炒,我總結一下,順便也把它算成一個特點。
事情是這樣的,DeepSeek在使用英偉達GPU訓練模型時,把132個流式處理器中的20個原來用於計算的,修改成負責服務器間通信傳輸,繞過了硬件對通信速度的限制。
修改使用的是英偉達PTX語言,而不是CUDA語言。有媒體言,DeepSeek使用底層匯編語言做優化,牛XPLUS。
用「人話」來解釋一下,程序語言是人和機器溝通的工具,是中間的對話翻譯。
英偉達的對話工具包括兩部分,底層翻譯PTX,高級翻譯CUDA。
程序員們日常工作都是與CUDA打交道,在CUDA上寫代碼,CUDA會翻譯給PTX,PTX再交由芯片執行。
DeepSeek為什麼不用CUDA,而使用底層翻譯直接開幹呢?
我猜有兩個原因,一是技術能力強,具備直接寫匯編語言的能力,一捅到底。
二是DeepSeek用的是H800芯片(制裁後專為國內市場出品,性能低於H100),後續被裁到H80(性能更低,美國自己都不用),萬一連CUDA這種翻譯也裁,用PTX起碼也算留個後手。
三是打通與芯片對話的全鏈條,以後也具備在其它友商GPU上復刻的可能性。真到英偉達全系列GPU芯片再被制裁出口的時候,其它GPU我也能做通。以上都是瞎猜的。
更重要的是,DeepSeek的R1本身就是推理模型,它編程不賴,能不能用它給自己寫PTX,DeepSeek有沒有這樣嘗試就不知道了。
這好像一個雞生蛋的循環。用PTX寫程序優化了R1,R1生成PTX的程序,寫出的程序還可以繼續優化R1。
07
DeepSeek強不強、新不新、抄沒抄,各有各的看法。
我說下自己對DeepSeek創新的評價:
從技術創新看,DeepSeek並沒有顛覆AI技術路線。甚至在創新程度上,遠未達到核彈級水平。
之前AI發展史的鋪墊可以看到,那些重要成果,是具有歷史意義的突破。RNN、BP、LSTM、DL……要麼是技術引領方向,要麼是路線理念開創。
DeepSeek最具價值的創新,在於研究過程中巧妙的設計、多種技術融合、同等強勁甚至略有領先的性能,以及體現出大幅提升的效率。
AI界的領頭羊OpenAI在2024年5月推出GPT-4o,9月發佈推理模型GPT-o1。
主要對手Anthropic公司2024年發佈最新模型Claude 3.5 Sonnet。
2024年友商這幾款產品的性能也一直在沿著平滑梯度升級。
只是DeepSeek這一輪短時間內費效比的提升幅度,比太平洋對岸友商快了太多,怎能讓人不側目。
從探索方向看,DeepSeek最為稱道的是堅持算法。
大語言模型有一個叫做規模化法則(Scaling Law)也稱尺度定律,被業界認為是大模型預訓練第一性原理。
簡單來說,就是隨著模型大小、數據集大小和計算資源的增加,堆越算力和數據,獲得的收益就會越大。俗稱越多越牛X。 然而,隨著模型規模的增大,每增加相同數量的參數或計算資源,獲得的性能提升逐漸減少,這叫做邊際效益遞減現象。
俗稱,卷不動了。
不是其它友商沒有在做算法,財大氣粗、兵強馬壯的OpenAI、Meta、Anthropic,都是不缺資源、不缺人才的主。
像DeepSeek這麼年輕又小的團隊,敢於打破傳統嘗試算法優化,並且做的通、做的好。這才是真的長臉。退一步說,就算DeepSeek做出的V3和R1略有不及友商的最新版本,那已經是了不起的成就了。
從歷史進程看,集中在語言大模型(LLM)競賽的各個團隊,很像二十年前我玩的一款MMORPG遊戲——魔獸世界(WOW)。
魔獸世界遊戲中,玩家組成40人(或25人)的團隊進入一個大型副本空間,一步步探索地圖、清理小怪,擊殺一個個守著關口的BOSS。
一直以來,美國、歐洲、亞洲地區各個服務器裡的優秀公會,在版本開放高級副本後,都會組織團隊在競速擊殺,看誰能用最少的時間通關。
但是,人工智能這個副本,路是未知的,最終BOSS在哪裡也是未知的,只有一步步的探索。
也許OpenAI的ChatGPT拿下第一個BOSS的世界首殺(FD,First Down),但其它公會也在第二、第三個BOSS上你追我趕,沒有誰是次次FD。
那麼今天,國服非知名公會DeepSeek,克服了刻意製造服務器延遲(芯片制裁),在極短時間內(成立不到1年半),集合一批新玩家組成團隊(211TOP高校應屆生等),裝備等級和藥品補給落後(成本顯著低於友商)的前提下,世界首殺第N個BOSS。
並且DeepSeek創設新的擊殺方法,擊殺後公佈技術文檔,製作擊殺視頻對全球玩家開放(開源)。
未來,會有更多的美服和國服公會拿到後面BOSS的首殺。
通向AI最終BOSS可能會像迷宮一樣,走其它探索擊殺的不同道路。
但是,這都不妨礙DeepSeek在這一輪書寫濃墨重彩一筆。
從社會影響看,人工智能的發展喚起全社會動力,從來不是出自實驗室,而是應用端的重大事件。
就像之前說過的,研究室裡的函數無法引起社會關注,廣告效應才會讓風投基金端著大把的金錢送到面前。
因為有IBM的超級計算機「沃森」在美國著名知識問答節目《危險邊緣》中戰勝兩名人類選手,自然語言處理(NLP)和人機交互才引發更多商業興趣。

因為有DeepMind的AlphaGo先後戰勝世界冠軍李世石和柯傑,大眾才關注到了深度神經網絡、無監督學習、強化學習、蒙特卡洛樹搜索。


因為有波士頓動力長期研發的四足機器人(Spot)和人形機器人(Atlas),並且開源了部分底層代碼,人們才看到越來越多的科研機構和初創企業做出更新更好的產品(2025年春晚亮相的宇樹科技產品)。
先行者在大洋彼岸,他們理所當然的認為創新的策源地在那裡,硅谷才是最好的科創環境。 但這一次,DeepSeek領先了一步。
「國運級別產品」評價雖有些過,但這也是很多燈塔國精英難以接受的。
看看Anthropic公司CEO Dario Amodei發佈的一篇頗有火藥味的所謂深度分析報告。
充滿了酸味與歧視,他所代表的那群人「不希望中國擁有強大的人工智能技術」,只有美國才有資格「取得支配且持久的領先地位」,必須「有效執行的出口管制」。
強盜邏輯。就像我之前說過的,「怎麼,你學習好還能補課就罷了,中學生還開始撕小學生的書本了。」
對DeepSeek芯片來源調查、對DeepSeek網絡攻擊、對DeepSeek涉隱私保護調查,有什麼下三濫的招數繼續使。看是誰在開放,誰在封閉。不排除某些口嫌體直,即當又立,一邊使用一邊喊打。
這回對線,DeepSeek和TikTok、華為不一樣。
08
下面,說一說我理解的DeepSeek中國式創新的本質。
1.大道求簡。中國古代的道家文化有個詞叫大道至簡,這原本並沒有寫在老子的《道德經》裡,是後人概括提煉出來,而與道家文化相吻合。
道家探索的「終極奧義」,追求簡單樸素的表達,不要繞彎,不要複雜,這是探索的出發點。
當堆硬件、壘資源的邊際效益已經出現遞減現象,DeepSeek沒有理由、也不願意跟從模仿複製已有方法。於是它改架構,做優化,創造更加精簡高效的模型生成範式。
當其他大模型創業公司抓住時間窗口把技術落到產品時,DeepSeek不參與融資,不設商業運營,不做產品變現,堅持做基礎模型和前沿創新。
保持技術團隊結構,減低世俗慾望,求簡的心態才能把最希望做的事做到更好。
一個東西能不能讓社會的運行效率變高,以及你能否在它的產業分工鏈條上找到擅長的位置。只要終局是讓社會效率更高,就是成立的。中間很多都是階段性的,過度關注必然眼花繚亂。
2.平衡求熵。DeepSeek追求的是平衡,不是極致。這個平衡包含算力與算法數據的平衡,投入與產出的平衡,時間與期望的平衡。
從「兩彈一星」到逐夢太空——窮則白手起家,富則節節開花。 從抗美援朝鮮到中越自衛反擊——窮則戰術穿插,富則火力覆蓋。
早在DeepSeek發佈V2模型後,就有人說它是行業的一條鯰魚,AI界的拼多多。這只是他們按自己步調的追求平衡的選擇。
面對芯片困境,DeepSeek沒有選擇退縮,反而激發了他們創新的潛能。 在技術競爭的高端領域,DeepSeek走平衡的特色之路,降低更多不確定性,也可能為今後的人為限制備有後手。這也為AI探索貢獻了更多中國式智慧、中國式方案。
3.胸懷求廣。從公開的DeepSeek CEO梁文鋒談話內容窺其觀點:
「我們不過是站在開源社區巨人們的肩膀上,給國產大模型這棟大廈多擰了幾顆螺絲。」——尊重過往
「當前最重要的不是商業化,而是參與全球創新的浪潮。」——力避短視
「在顛覆性的技術面前,閉源形成的護城河是短暫的。即使OpenAI閉源,也無法阻止被別人趕超。」——堅持開源
DeepSeek發佈每一個版本的同時,都在發論文、做開源、談不足,甚至提建議。他們追求的是,吸引更多參力量與共建,創設一個屬於中國的AI社區生態。
為什麼需要AI社區生態?因為有了足夠廣闊充實的技術社區生態,加以中國本不缺乏的豐富產業應用場景,這片土地才可能看到下一代的技術趨勢,而不是未戰先自怯、且戰且圈錢,或是亂戰盲跟從。
4.機制求變。什麼樣的團隊,什麼樣的工作機制,才能造就這樣的DeepSeek。
梁文鋒自己說,他們並沒有什麼高深莫測的奇才,都是一些Top高校的應屆生、沒畢業的博四、博五實習生,還有一些畢業才幾年的年輕人。
DeepSeek的運作體系並不拘泥於傳統的管理模式。團隊成員可以靈活調用訓練集群的資源,而不必經過繁瑣的審批過程。
DeepSeek在V2和V3時,創新運用了使用多頭潛在注意力(MLA)技術,這個突發奇想的設計來自團隊的一員,DeepSeek立刻圍繞他成立一個小組,上人上卡上資源。
梁文鋒說,在不確定的前沿探索上,DeepSeek是自上而上,不前置分工而是自然分工,看到潛力時再自上而上去調配資源。
這種自由的探索精神,充分體現了創新組織的特質。
不客氣的說,大廠和編內機構有多少弊病,掰著指頭數不過來。
層級複雜,審批繁瑣,內耗嚴重,方向多變,形式主義,摸魚躺平……
AI競速上如果沾染這些,空有一身抱負也無殺賊之力。DeepSeek給同行打了樣,讓更多強熱愛驅動的人迸發才智。
09
2025年的第一個月,繼DeepSeek後的短短幾天,抖音發佈豆包1.5 Pro,阿里巴巴發佈Qwen 2.5-Max,OpenAI發佈GPT-o3系列。
競速仍在繼續,創新永無止盡。
大語言模型如此執著的比拼,是不是通向通用人工智能(AGI)的未來?
當算力算法數據的邊際效益,遞減到費大力卷出一個遠不及期望的低級智能體時,會不會再次迎來AI寒冬? 無數的未知只能留給賽道上的優秀選手。
當下,中國在AI賽道上與美國差距仍大,幅度縮小。需要更多DeepSeek式勇者破浪前行。
勢在我,時未及,以勢待時。
面對美國政府對華制裁和Anthropic公司CEO Dario Amodei挑釁,希望有一天,能聽到類似楊潔篪2021年在安克雷奇對話時的發言:
「你們沒有資格在中國的面前說,你們從實力的地位出發同中國談話。」



Be the first to comment